
W poprzednim artykule dotyczącym relacji między tabelami dowiedzieliśmy się, że można łączyć w różny sposób ze sobą tabele i dzięki temu zwracać zbiór interesujących nas danych. Wykorzystamy tę wiedzę, by tym razem wykonać różne operacje na rekordach.
Wykorzystanie relacji między tabelami z użyciem UPDATE
Wróćmy na chwilę do naszego pierwszego artykułu, w którym mieliśmy dwie tabele:
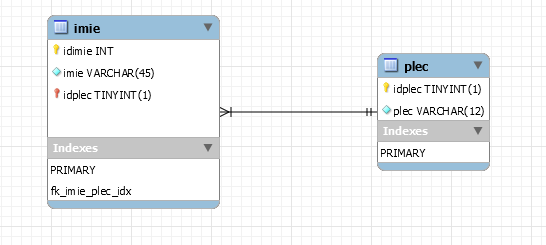
Wyobraźmy sobie teraz sytuację, że chcemy wprowadzić frazę kobieta w kolumnie imie, wszędzie tam, gdzie płeć jest żeńska. Możemy to zrobić w ten sposób:
Update `imie` SET imie=’kobieta’ WHERE `idplec` = 1;
Pytanie tylko skąd pewność, że liczba 1 jest prawidłowa? Teoretycznie łatwo możemy to sprawdzić zaglądając do tabeli plec. Jednak w przypadku operacji na większej ilości danych, może to być problematyczne.
Spróbujmy zatem użyć relacji. Najpierw postarajmy się połączyć imiona z płcią:
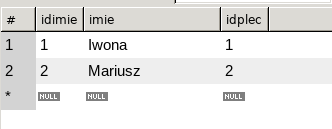
SELECT
i.*, p.`plec`
FROM
`imie` i
JOIN
`plec` p ON i.`idplec` = p.`idplec`

W kolejnym kroku wybierzmy tylko imiona żeńskie:
SELECT
i.*, p.`plec`
FROM
`imie` i
JOIN
`plec` p ON i.idplec = p.`idplec` and p.`plec` = 'kobieta'
To było proste prawda? Dodaliśmy do naszego warunku and p.`plec` = 'kobieta' i już 🙂
Teraz gdy już jesteśmy pewni naszego warunku możemy przeprowadzić update:
UPDATE `imie` i
JOIN
`plec` p ON i.`idplec` = p.`idplec`
AND p.`plec` = 'kobieta'
SET
i.`imie` = 'kobieta';
Możemy też przenieść wartość z jednej tabeli do drugiej, w tym przypadku nazwę płci:
UPDATE `imie` i
JOIN
`plec` p ON i.`idplec` = p.`idplec`
AND p.`plec` = 'kobieta'
SET
i.`imie` = p.`plec`;
Aby sprawdzić poprawność wykonanej operacji, należy wykonać zapytanie:
SELECT * FROM `imie`;
Wykorzystanie relacji między tabelami z użyciem DELETE
Podobnie możemy wykorzystać relację, aby usunąć rekordy, które spełniają określone cechy zdefiniowane w innych tabelach.
Stwórzmy sobie na potrzeby testu poniższe tabele:
CREATE TABLE `gatunki_muzyczne` (
`idgatunki_muzyczne` int(11) NOT NULL AUTO_INCREMENT,
`nazwa` varchar(45) NOT NULL,
PRIMARY KEY (`idgatunki_muzyczne`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8_general_ci;
CREATE TABLE `preferencje` (
`idpreferencje` int(11) NOT NULL AUTO_INCREMENT,
`idgatunki_muzyczne` int(11) NOT NULL,
`idimie` int(11) NOT NULL,
`preferencja` enum('tak','nie') NOT NULL,
PRIMARY KEY (`idpreferencje`),
KEY `fk_preferencje_1_idx` (`idgatunki_muzyczne`),
KEY `fk_preferencje_2_idx` (`idimie`),
CONSTRAINT `fk_preferencje_1` FOREIGN KEY (`idgatunki_muzyczne`) REFERENCES `gatunki_muzyczne` (`idgatunki_muzyczne`) ON DELETE CASCADE ON UPDATE CASCADE,
CONSTRAINT `fk_preferencje_2` FOREIGN KEY (`idimie`) REFERENCES `imie` (`idimie`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8_general_ci;
Zasilmy tabele danymi:
INSERT INTO `gatunki_muzyczne` (`nazwa`) VALUES ('rap');
INSERT INTO `gatunki_muzyczne` (`nazwa`) VALUES ('rock');
INSERT INTO `gatunki_muzyczne` (`nazwa`) VALUES ('disco-polo');
INSERT INTO `preferencje` (`idgatunki_muzyczne`, `idimie`, `preferencja`) VALUES ('1', '1', 'tak');
INSERT INTO `preferencje` (`idgatunki_muzyczne`, `idimie`, `preferencja`) VALUES ('2', '1', 'tak');
INSERT INTO `preferencje` (`idgatunki_muzyczne`, `idimie`, `preferencja`) VALUES ('3', '1', 'nie');
INSERT INTO `preferencje` (`idgatunki_muzyczne`, `idimie`, `preferencja`) VALUES ('1', '2', 'nie');
INSERT INTO `preferencje` (`idgatunki_muzyczne`, `idimie`, `preferencja`) VALUES ('2', '2', 'tak');
INSERT INTO `preferencje` (`idgatunki_muzyczne`, `idimie`, `preferencja`) VALUES ('3', '2', 'nie');
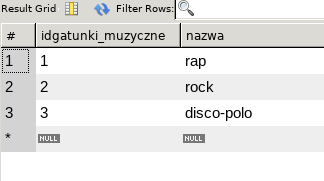
Spróbujmy teraz wyświetlić wszystkie gatunki muzyczne:
SELECT * FROM `gatunki_muzyczne`;
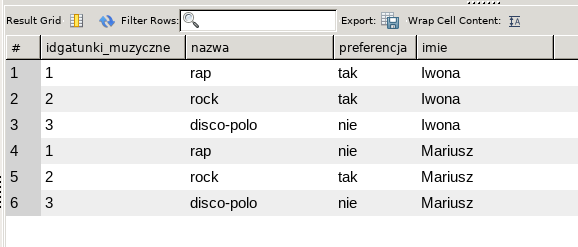
Dodajmy do tego użytkowników i ich preferencje:
SELECT
g.*, p.`preferencja`, i.`imie`
FROM
`gatunki_muzyczne` g
JOIN
`preferencje` p ON p.`idgatunki_muzyczne` = g.`idgatunki_muzyczne`
JOIN
`imie` i ON p.`idimie` = i.`idimie`
Znajdźmy teraz wszystkie te gatunki, których Mariusz i Iwona wspólnie nie lubią:
SELECT
g.*, count(g.`idgatunki_muzyczne`) as `uzytkownicy`
FROM
`gatunki_muzyczne` g
JOIN
`preferencje` p ON p.`idgatunki_muzyczne` = g.`idgatunki_muzyczne` and `preferencja` = 'nie'
JOIN
`imie` i ON p.`idimie` = i.`idimie`
GROUP BY `nazwa`
HAVING `uzytkownicy` = (select count(*) from `imie`)

Ok to zapytanie może być w Twoich oczach naprawdę hardcorowe. Omówmy więc co się wydarzyło:
- Wyrzuciliśmy z poprzedniego zapytania kolumny:
preferencjaiimie, ponieważ już nie są nam potrzebne – przejrzeliśmy dostępne rekordy i upewniliśmy się, że Iwona i Mariusz nie lubiądisco polo. - Dodaliśmy kolumnę
uzytkownicyliczoną “w locie”, która zawiera liczbę użytkowników, którzy mają taką samą preferencję - Pogrupowaliśmy wyniki, aby nie otrzymać zdublowanych pozycji i móc wyliczyć ilość osób, które nie lubią
disco polo - Użyliśmy kwerendy
HAVING, aby operując na wyniku wybrać tylko te wiersze, które zawierają w sobie informacje o tym, że wszyscy użytkownicy nie lubią disco polo. W kwerendzie tej dodaliśmy warunek: wartość kolumnyuzytkownicy(wyliczonej w locie) musi się równać sumie użytkowników z tabeliimie.
Ok, więc mamy interesującą nas nazwę gatunku muzycznego, który chcemy usunąć:
DELETE FROM `gatunki_muzyczne`
WHERE
`idgatunki_muzyczne` IN (SELECT
`idgatunki_muzyczne`
FROM
(SELECT
g.*, COUNT(g.`idgatunki_muzyczne`) AS `uzytkownicy`
FROM
`gatunki_muzyczne` g
JOIN `preferencje` p ON p.`idgatunki_muzyczne` = g.`idgatunki_muzyczne`
AND `preferencja` = 'nie'
JOIN `imie` i ON p.`idimie` = i.`idimie`
GROUP BY `nazwa`
HAVING `uzytkownicy` = (SELECT
COUNT(*)
FROM
`imie`)) subquery)
Owww… 🙂 wygląda jeszcze groźniej 🙂 Tak naprawdę to jest bardzo proste. Z naszego poprzedniego zapytania potrzebujemy tylko idgatunki_muzyczne, aby wiedzieć który rekord usunąć. Musimy więc wybrać tylko tę kolumnę. Dokonamy tego, dzięki zastosowaniu podzapytania (select w select). Z kolei w samej kwerendzie DELETE podajemy warunek, że interesuje nas usunięcie tylko tych rekordów, których idgatunki_muzyczne zawiera się w zbiorze, który zwróciliśmy.
Aby potwierdzić prawidłowe wykonanie operacji wyświetlmy aktualny stan tabeli:
SELECT * FROM `gatunki_muzyczne`;